Tonghe Zhang1, Chao Yu2, Sichang Su3, Yu Wang2
1 Carnegie Mellon University 2 Tsinghua University 3 University of Texas at Austin
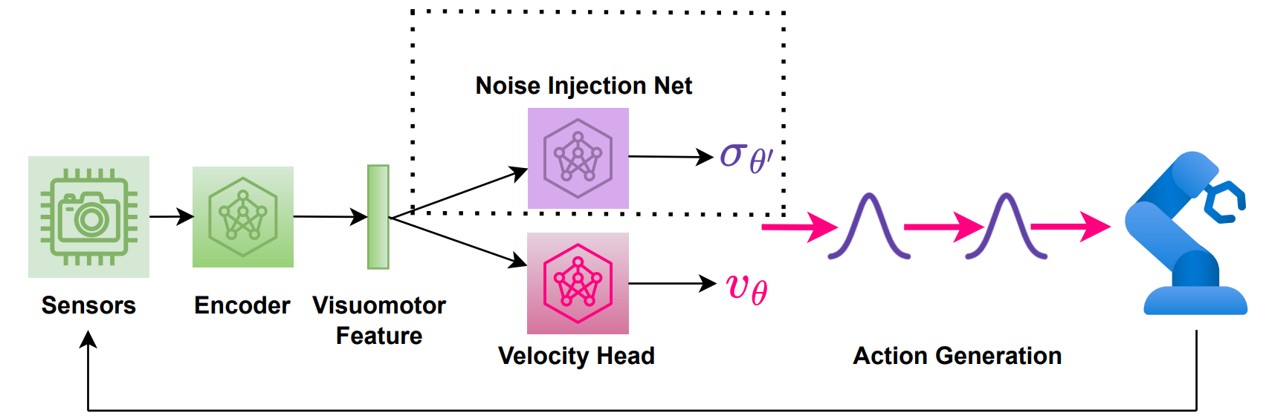
Fine-tuning flow matching policy with ReinFlow involves these steps:
| Input Type | Reward Type | Environment | Data Source |
|---|---|---|---|
| State | Dense | OpenAI Gym | D4RL data |
| State | Sparse | Franka Kitchen | Human-teleoperated data from D4RL |
| Visual | Sparse | Robomimic | Human-teleoperated data processed like DPPO's paper |
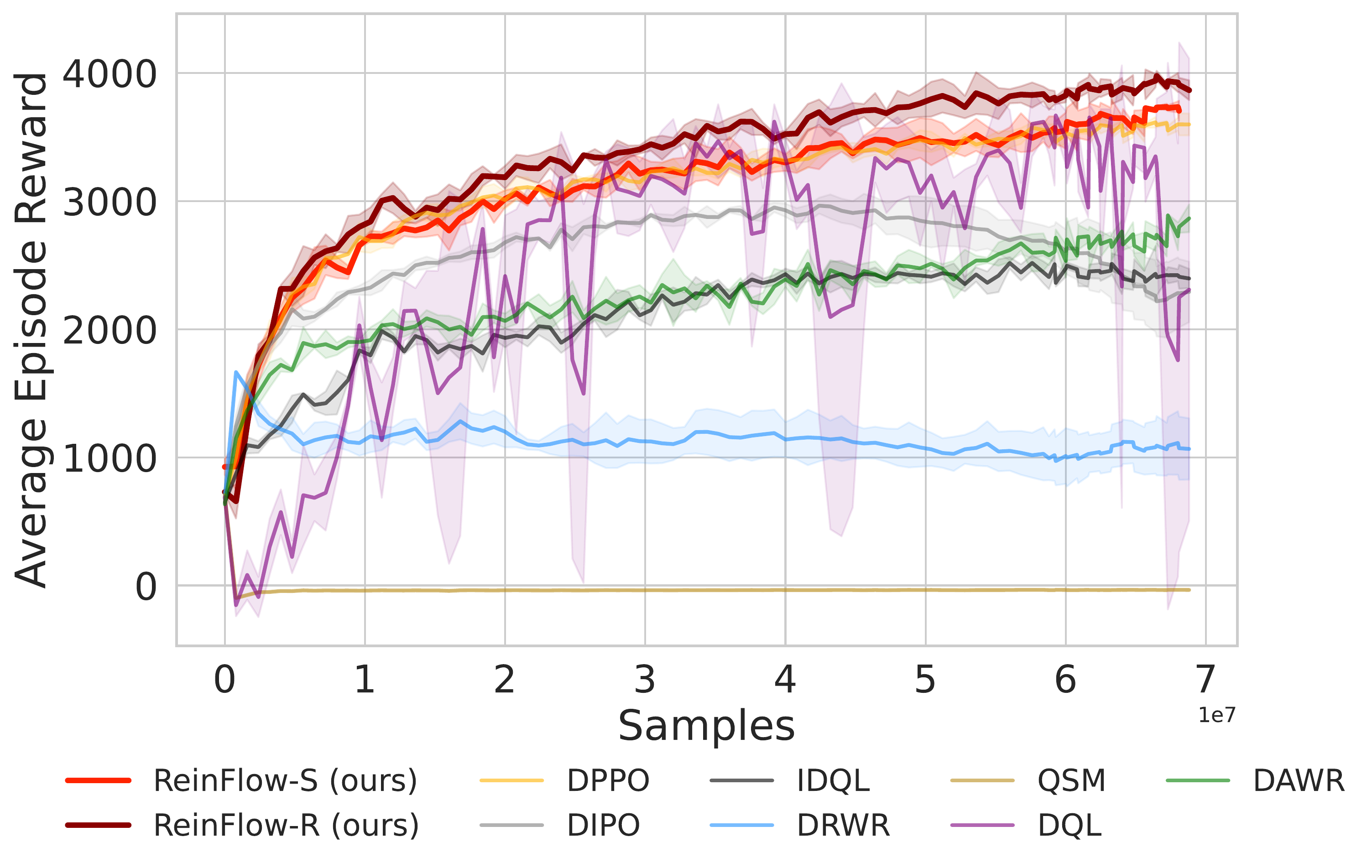
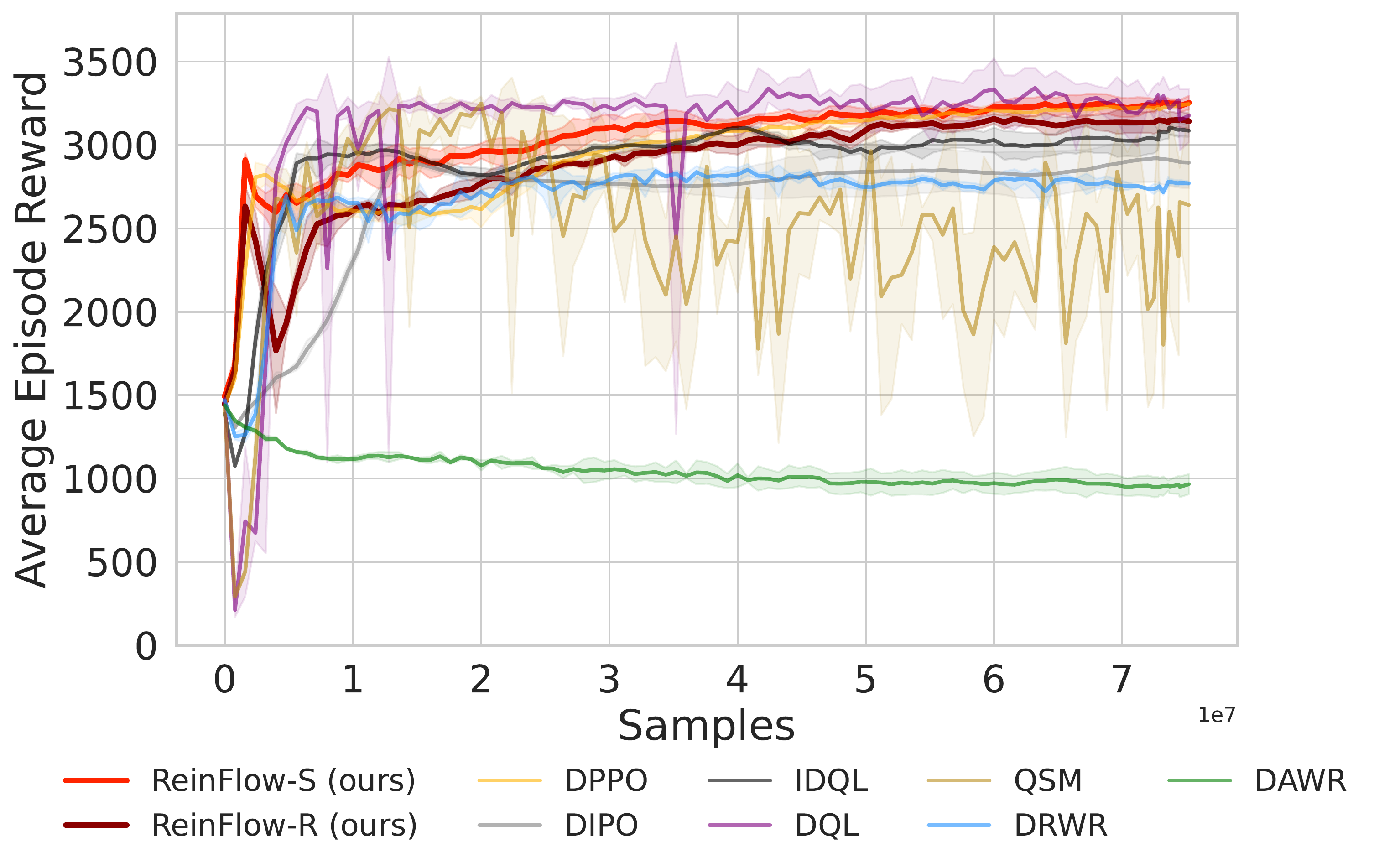
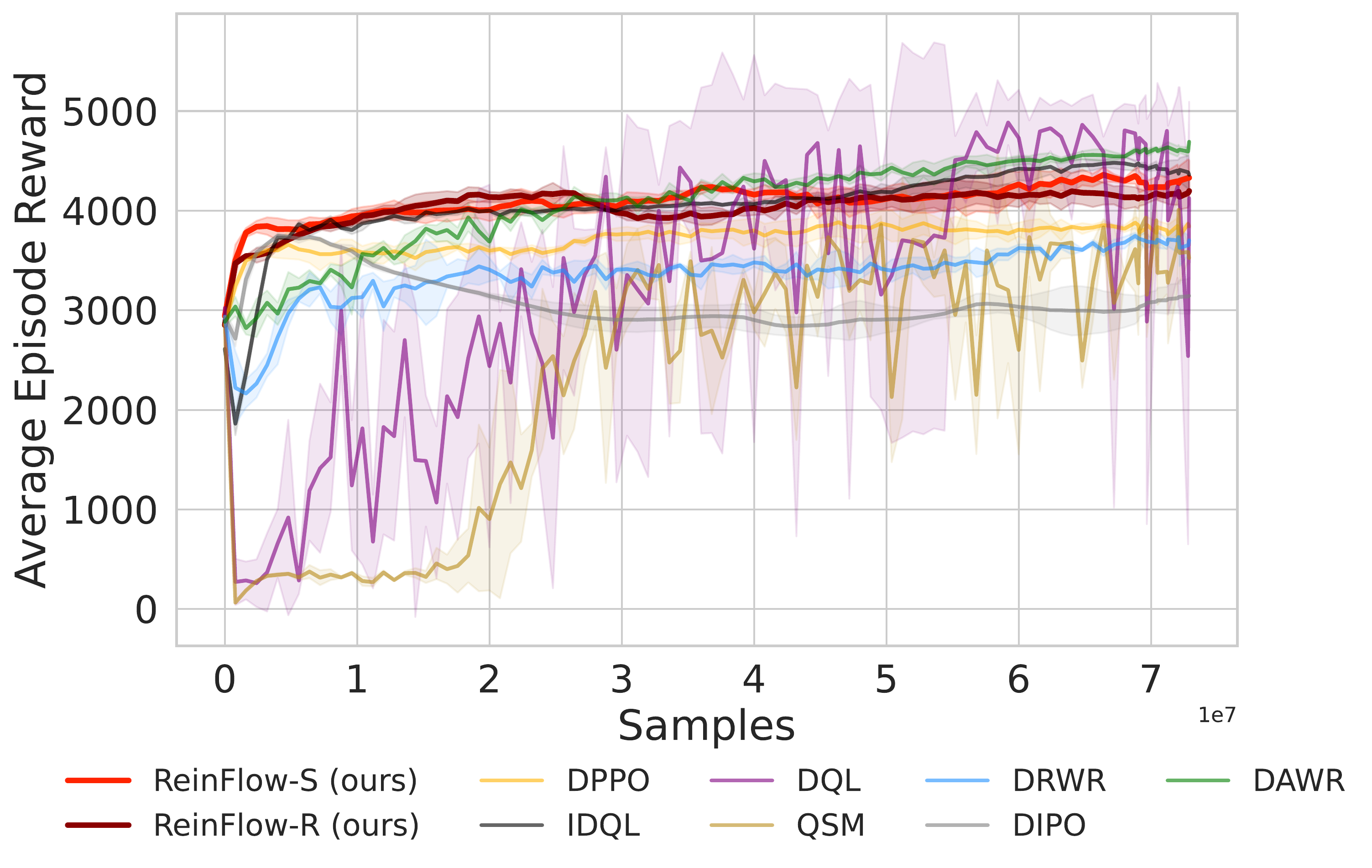
📈 ReinFlow consistently enhances performance across Gym and Franka Kitchen benchmarks, boosting success rates by 40.09% in Robomimic tasks with fewer steps than DPPO.
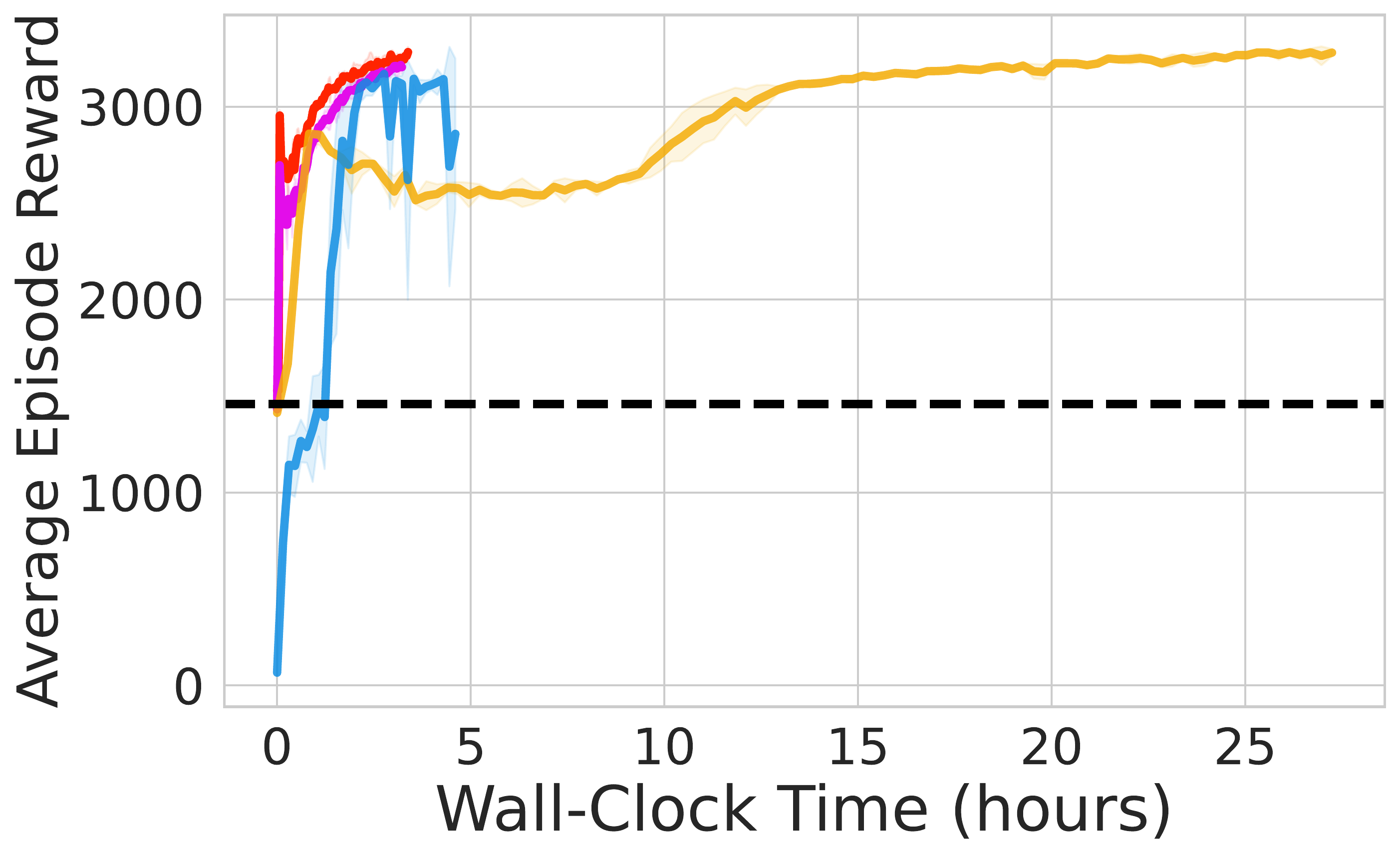
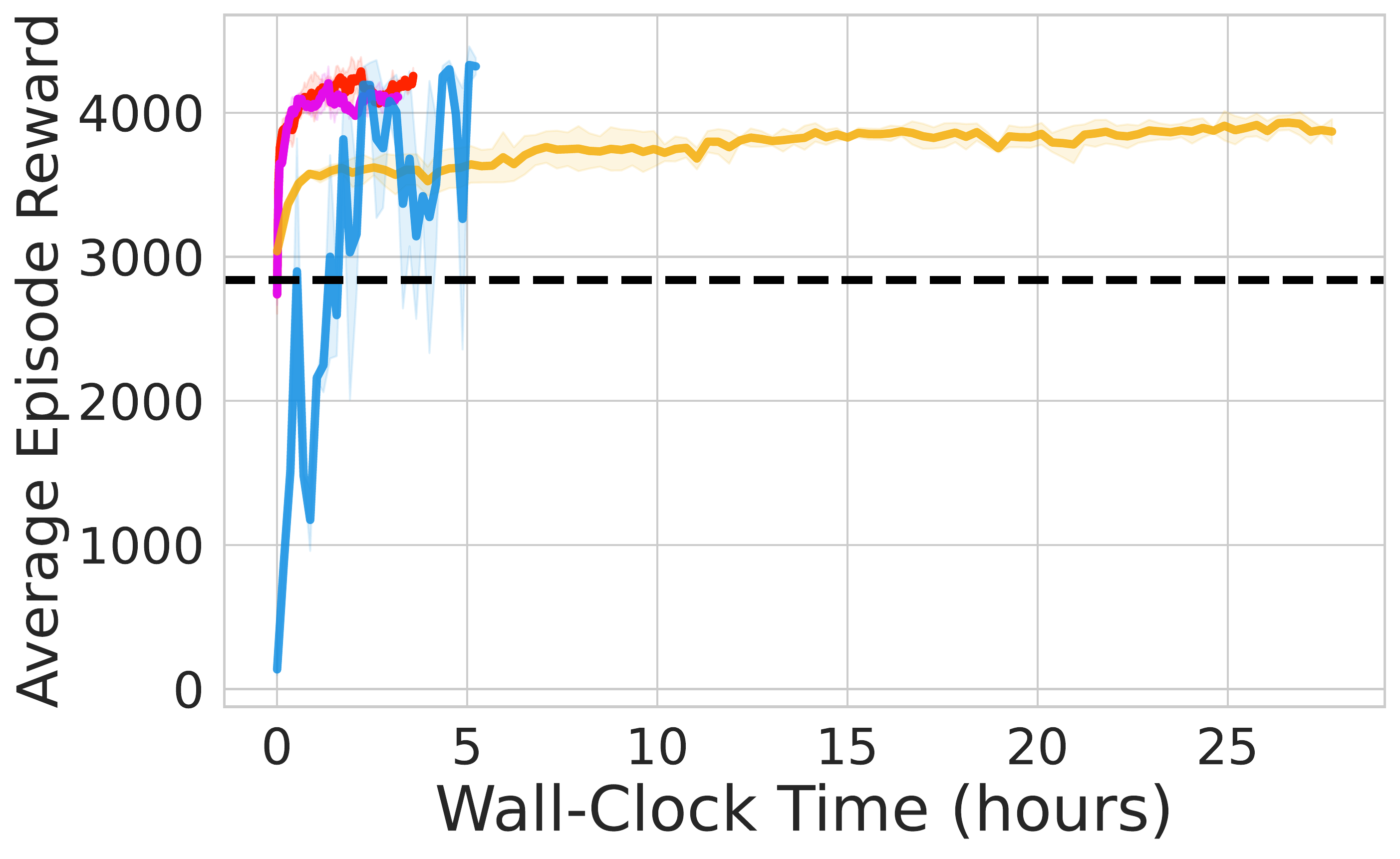
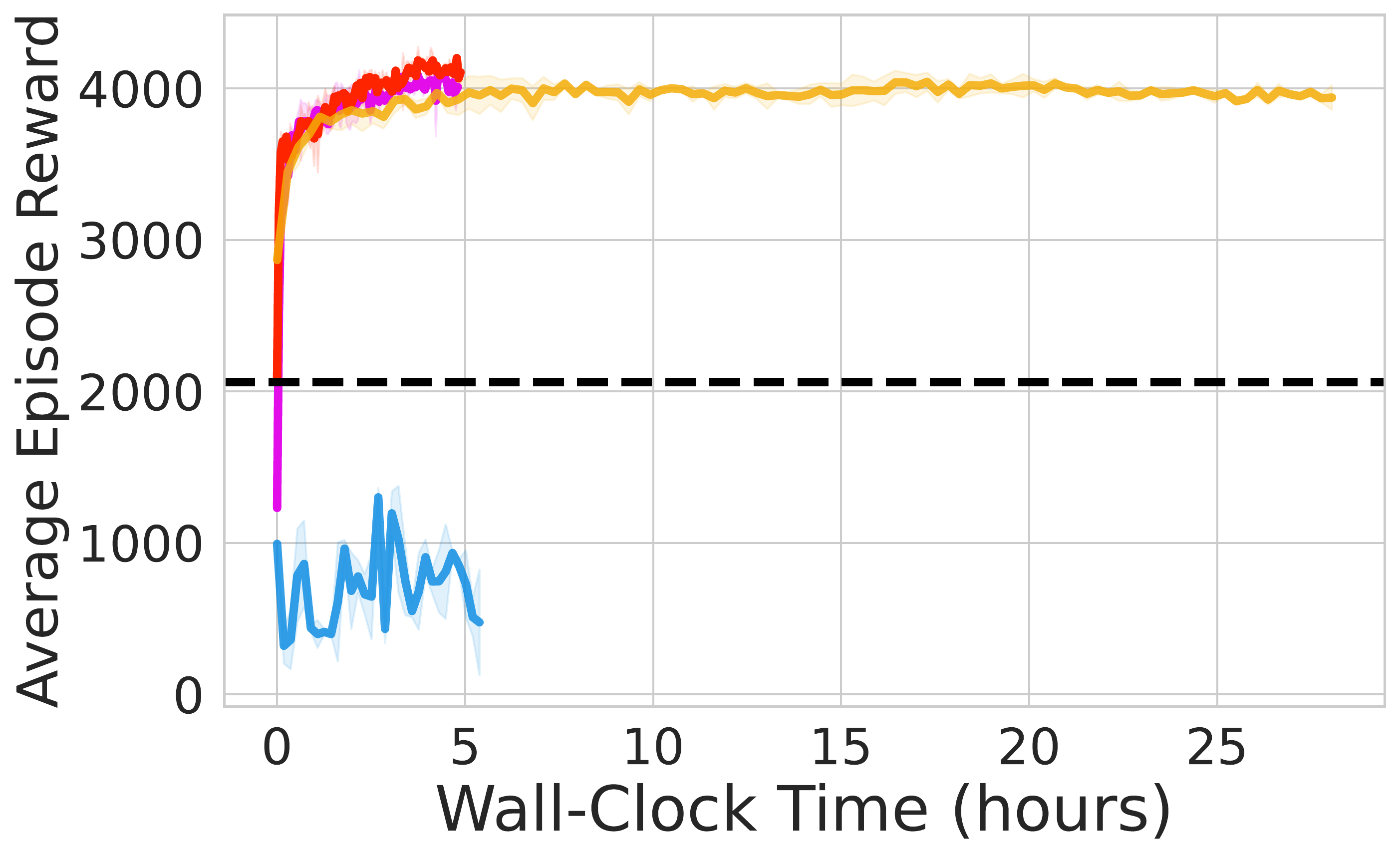
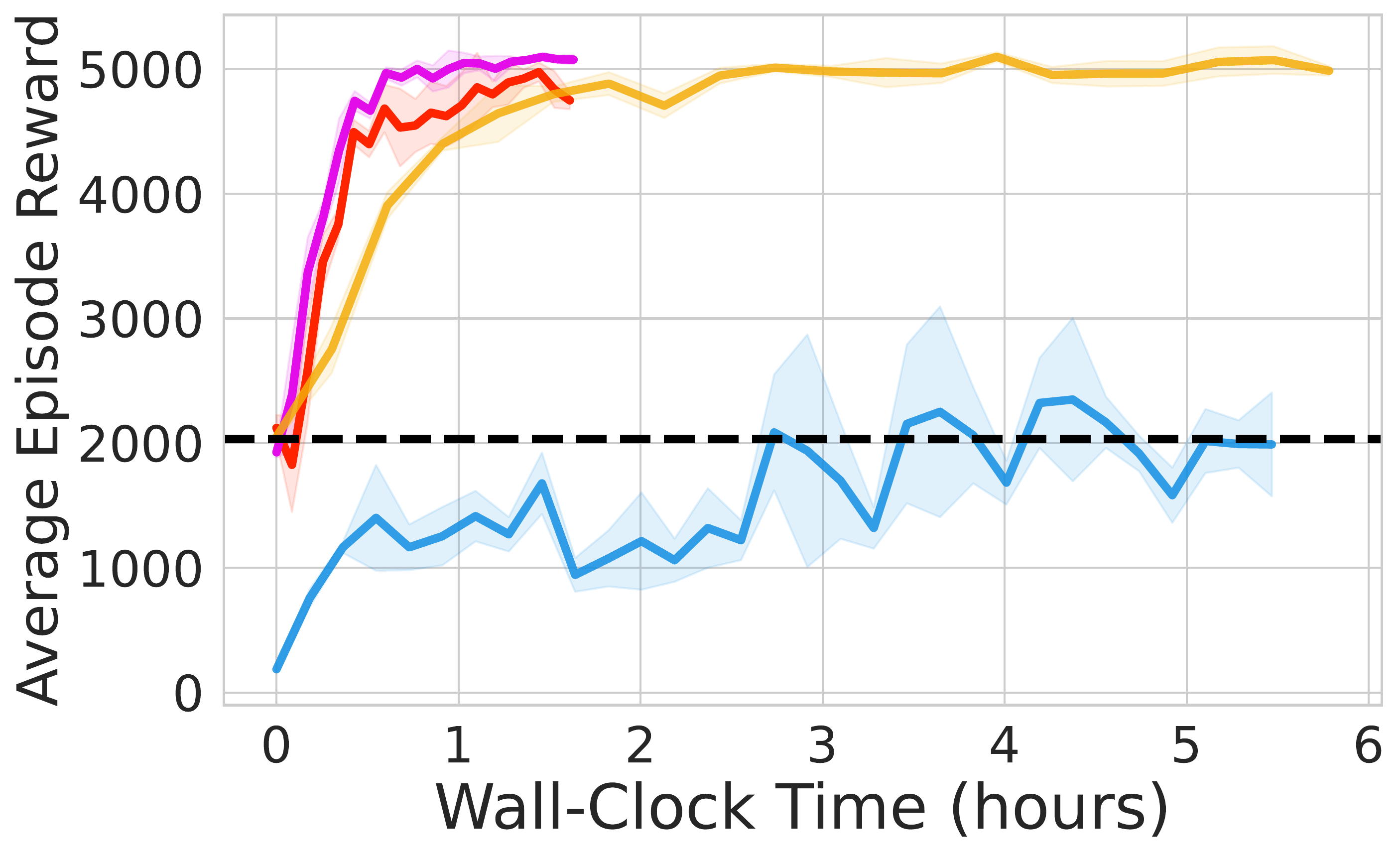

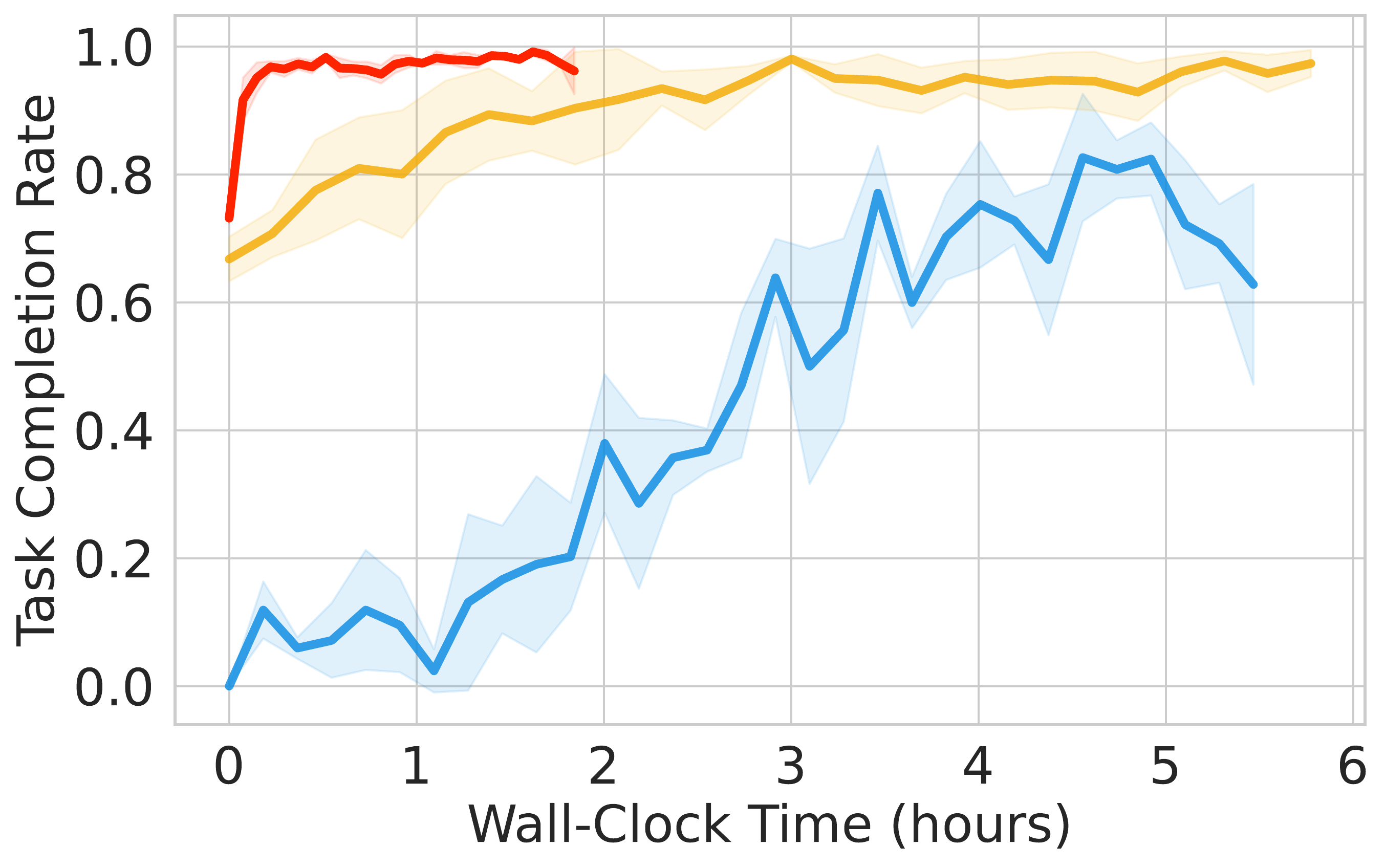
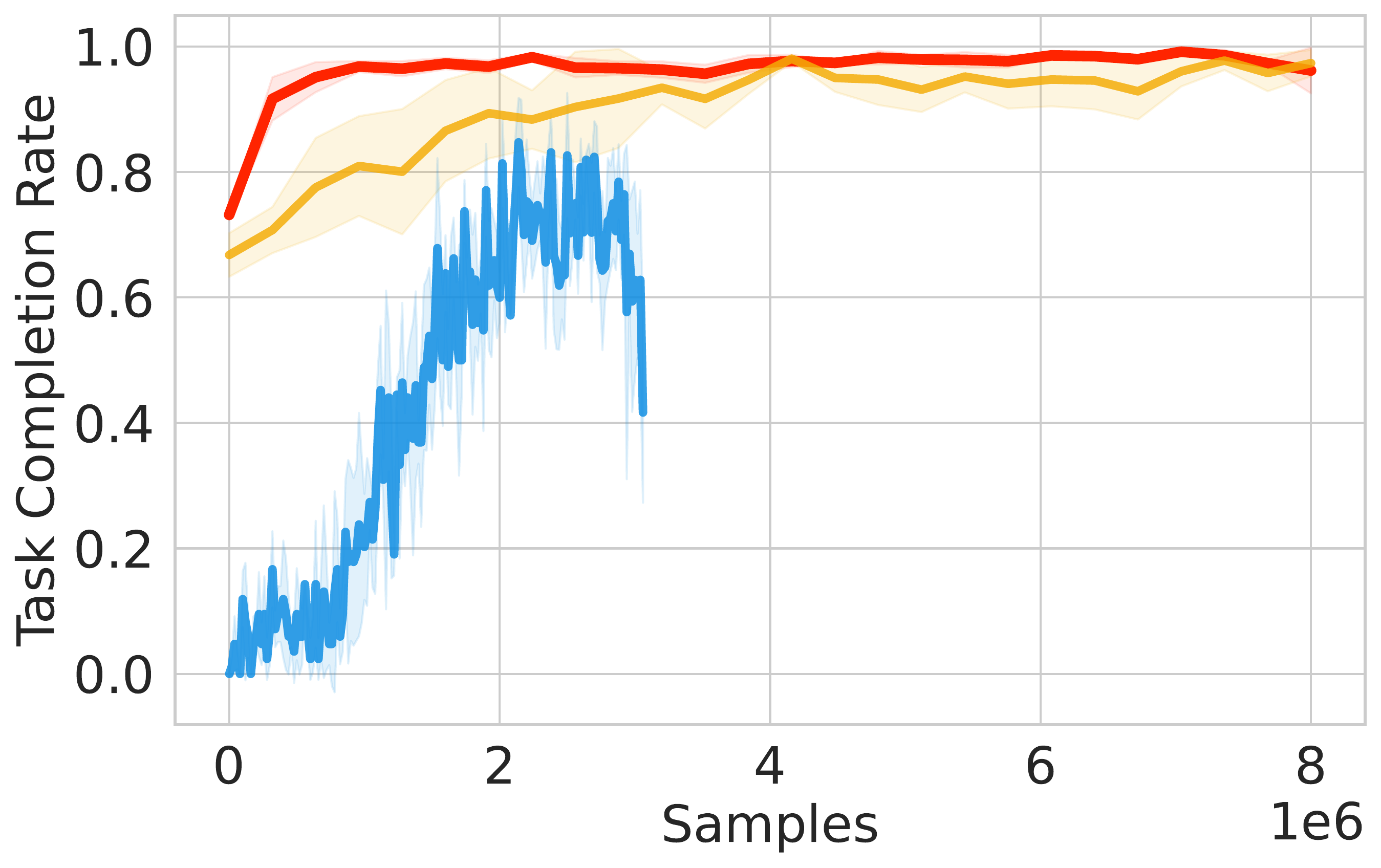
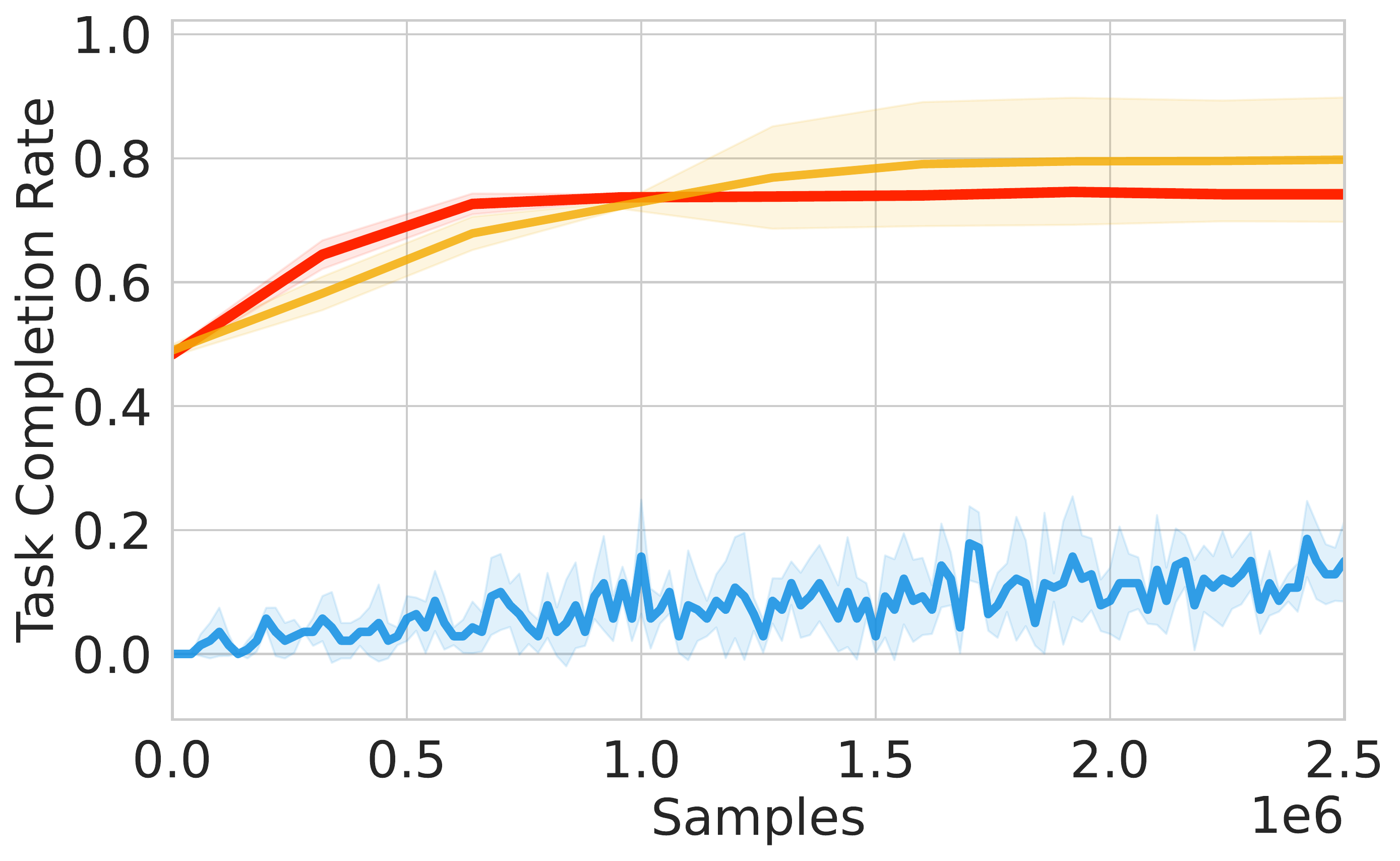
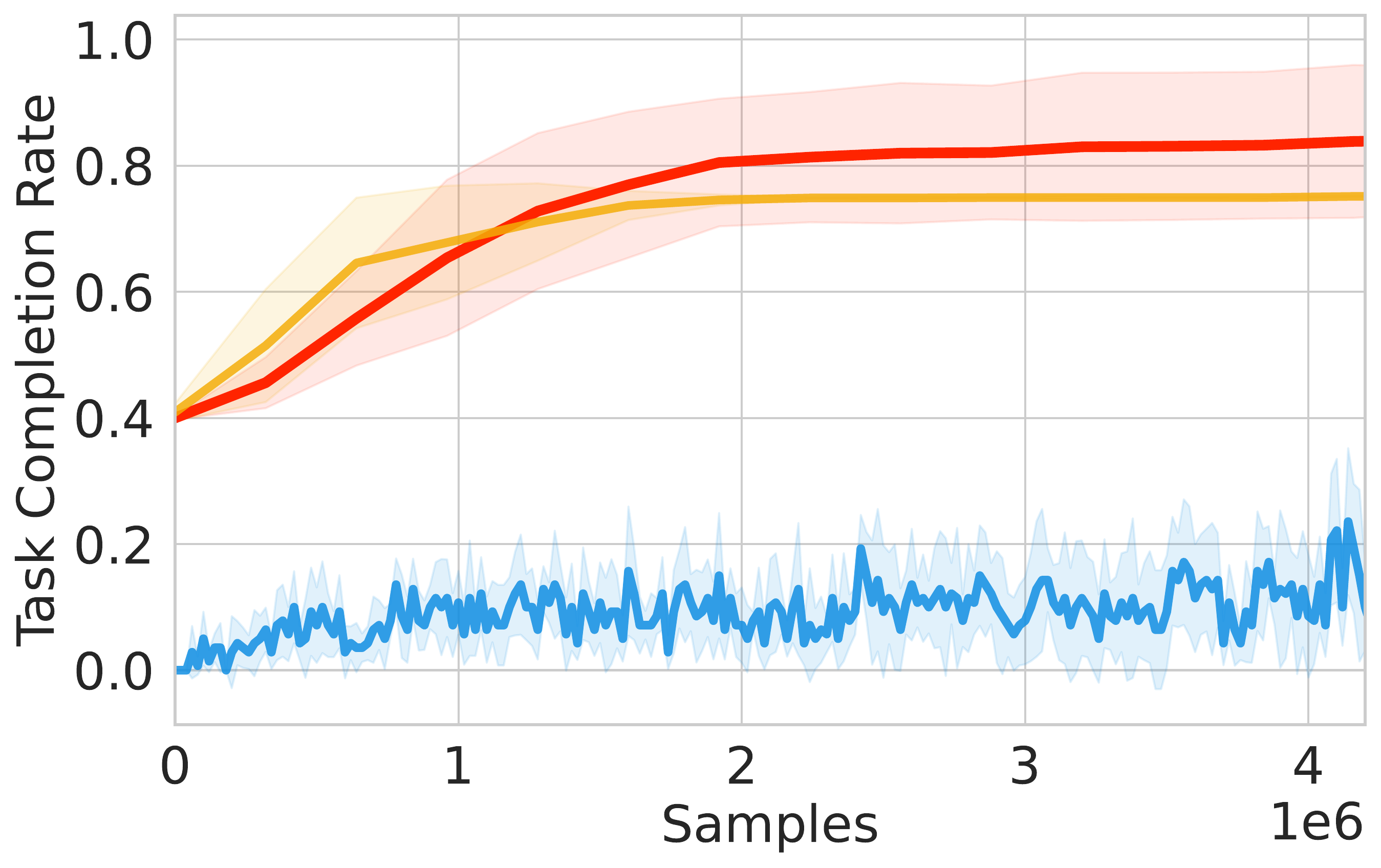

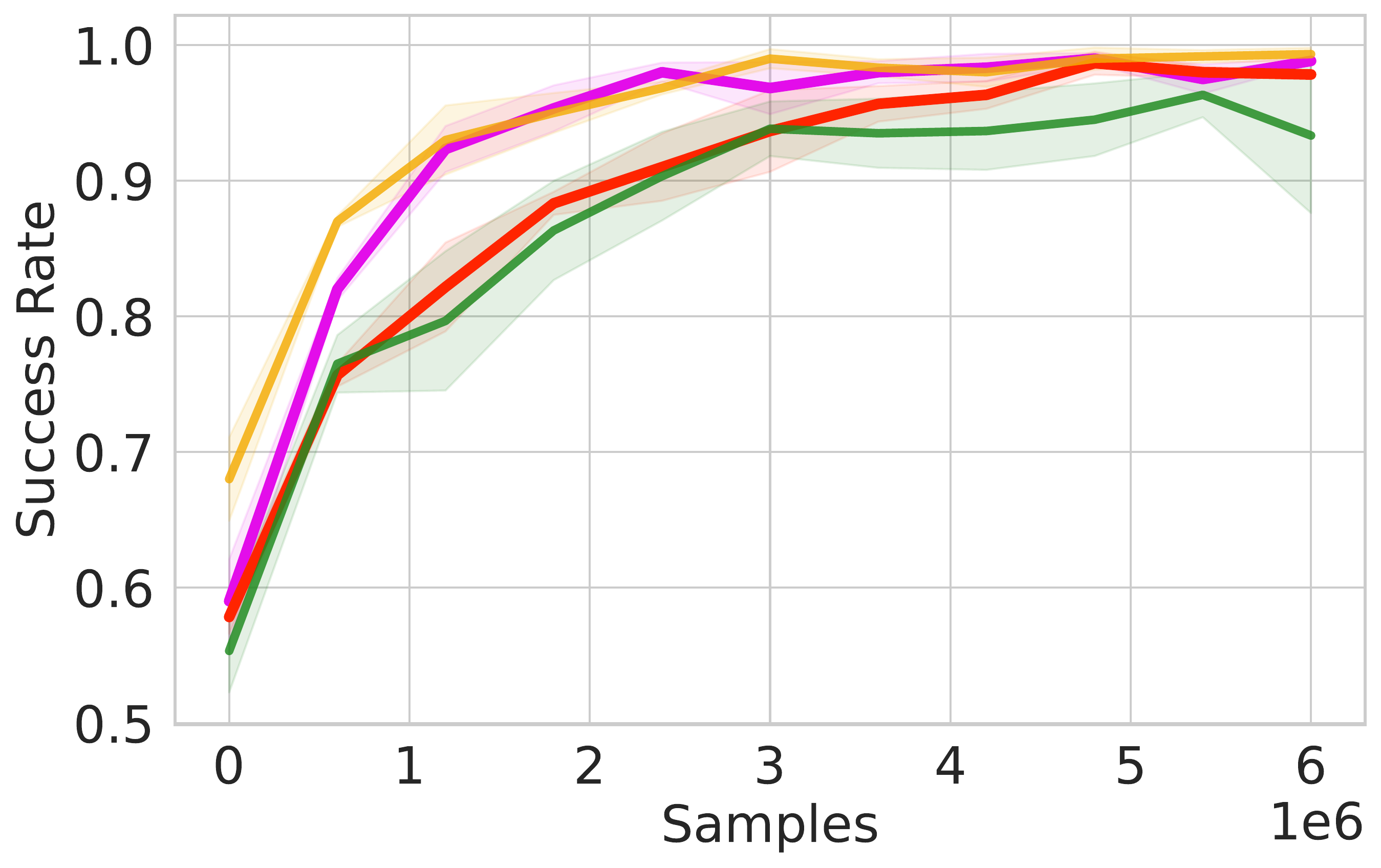
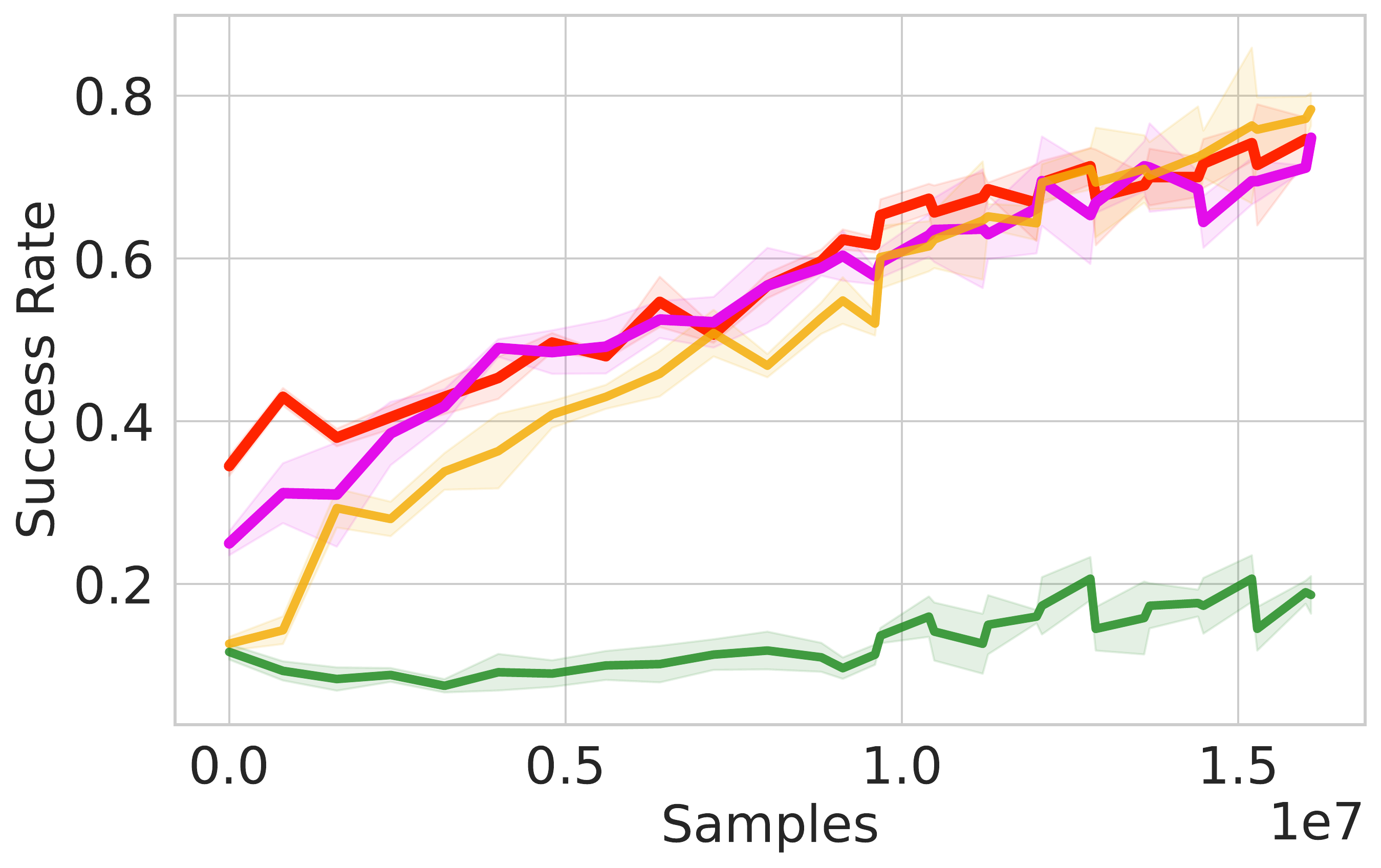
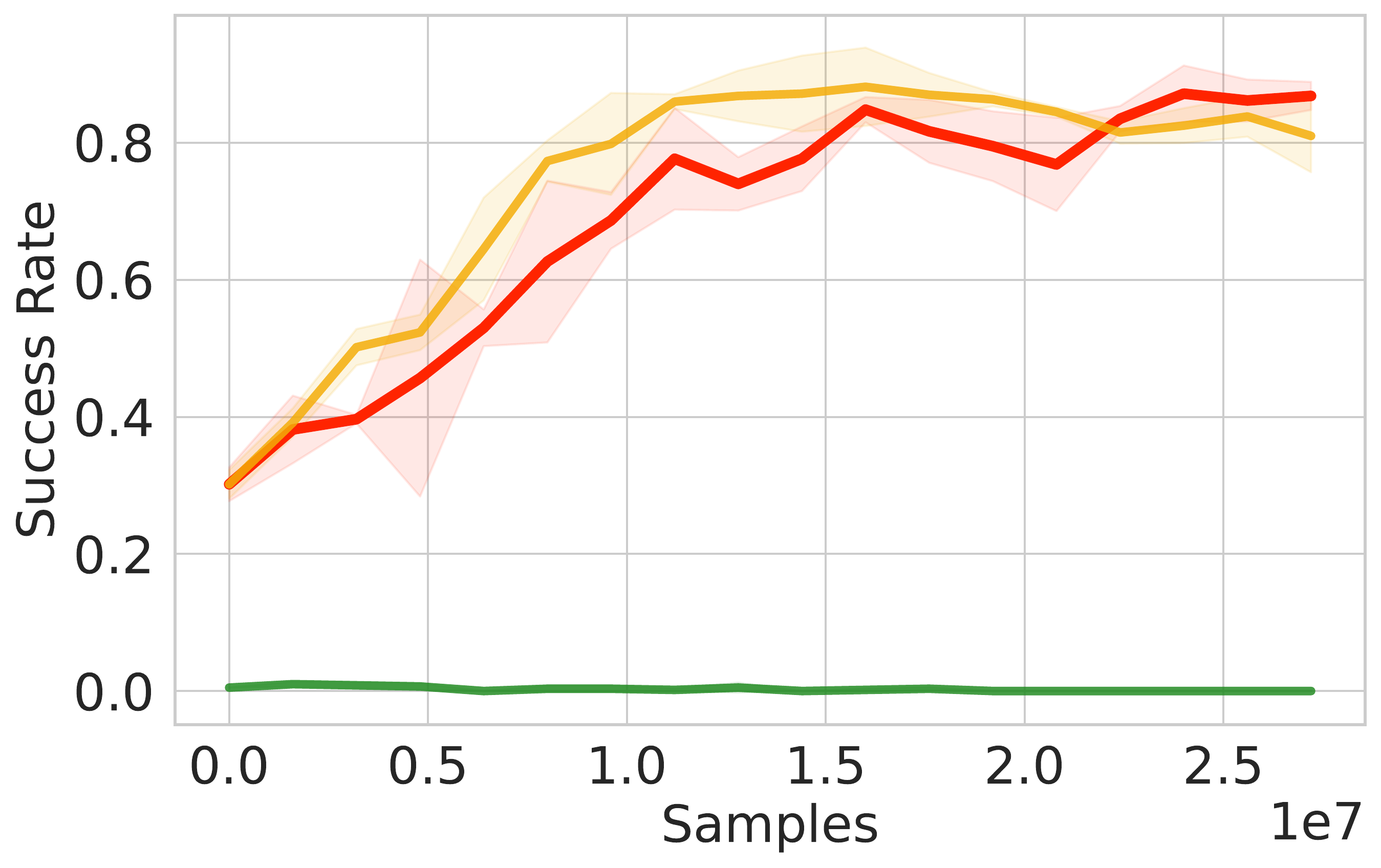

⚖️ ReinFlow outperforms diffusion RL baselines in stability and asymptotic performance across continuous control tasks like Ant-v0, Hopper-v2, and Walker2d-v2.
📊 Using consistent hyperparameters from prior work, ReinFlow demonstrates superior performance, as shown in Fig. 5(A-C).
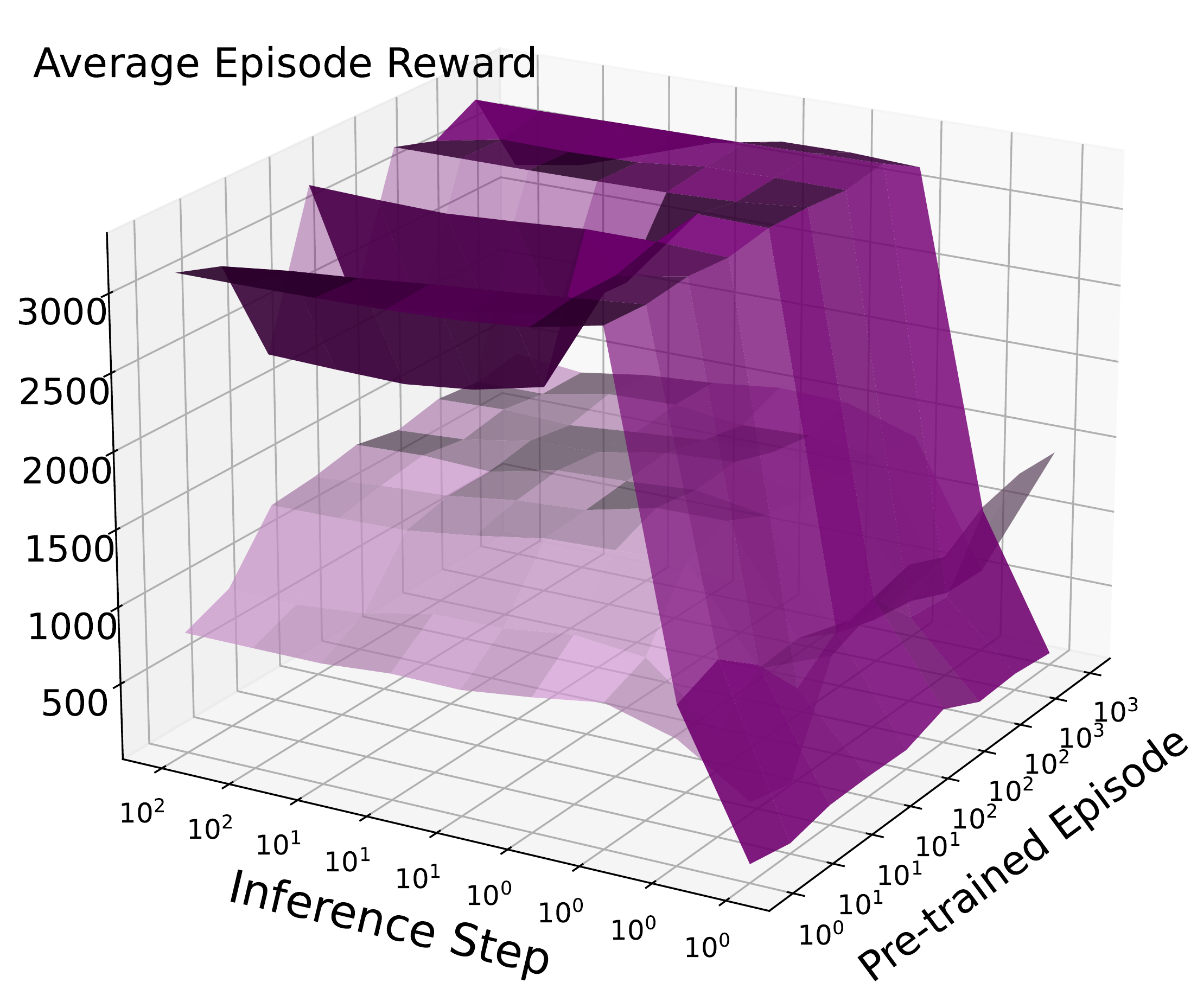
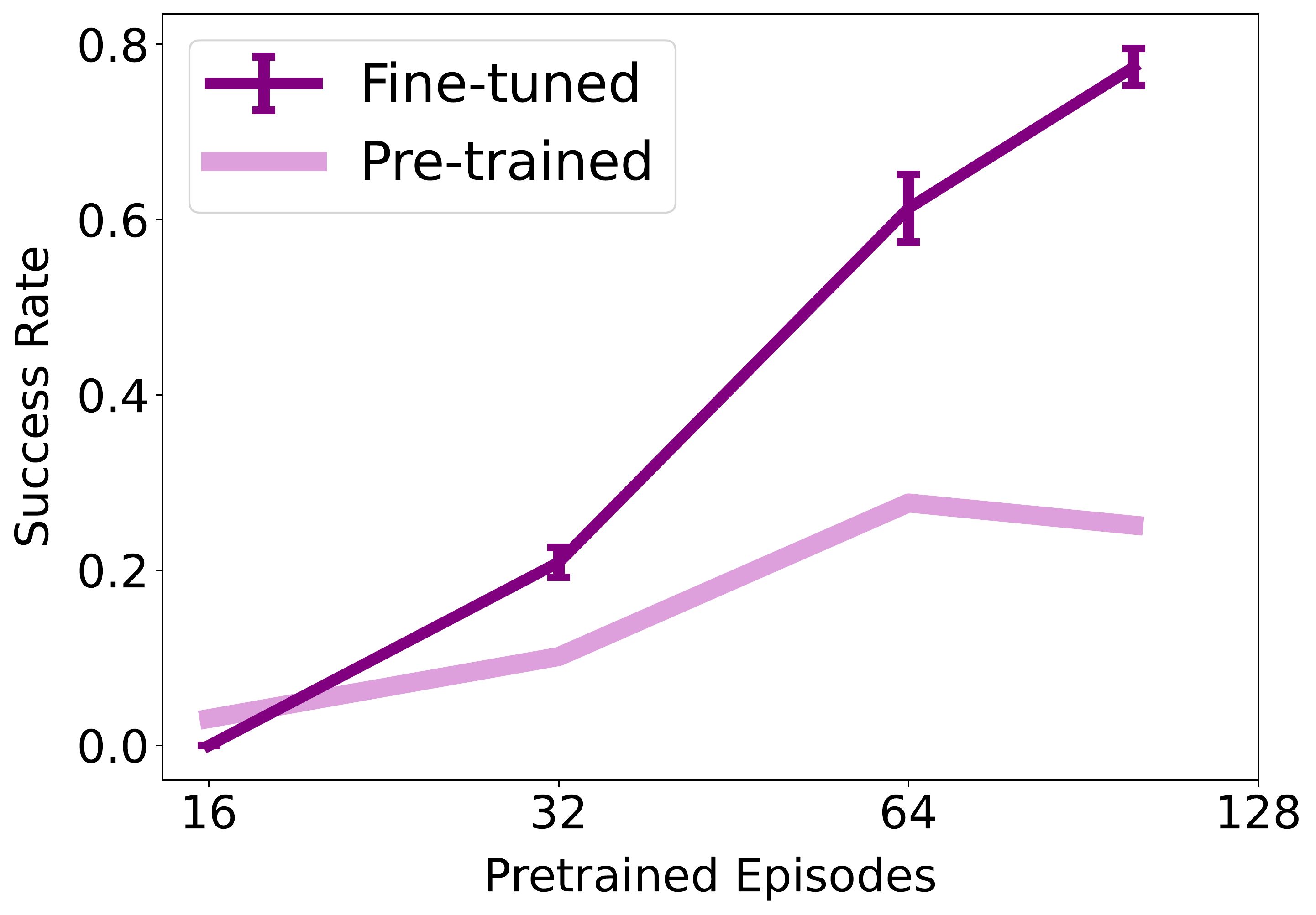
We examine how pre-trained models, denoising steps, noise levels, regularization and denoising step number impact ReinFlow.
➖
Scaling data or inference steps: quickly plateaus.
📈 Fine-tuning with RL (ReinFlow): consistently enhances performance.
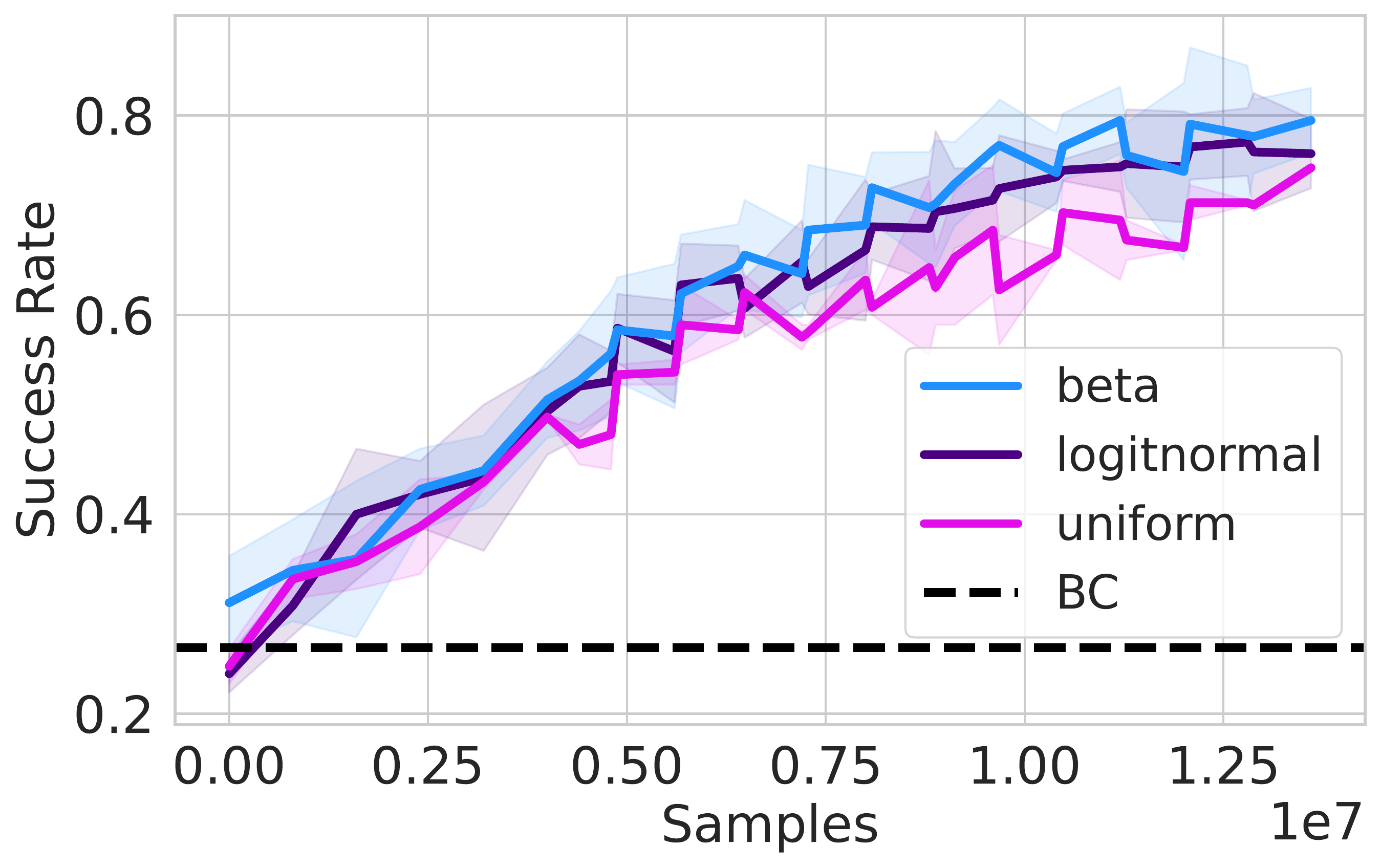
ReinFlow's performance is robust to changes in time sampling.
✅ Uniform
✅ Logit-normal
✅ Beta (slightly better for single-step fine-tuning.)
Conditioning noise on state alone works well.
Conditioning noise on both state and time generates more diverse actions and improves success rates.
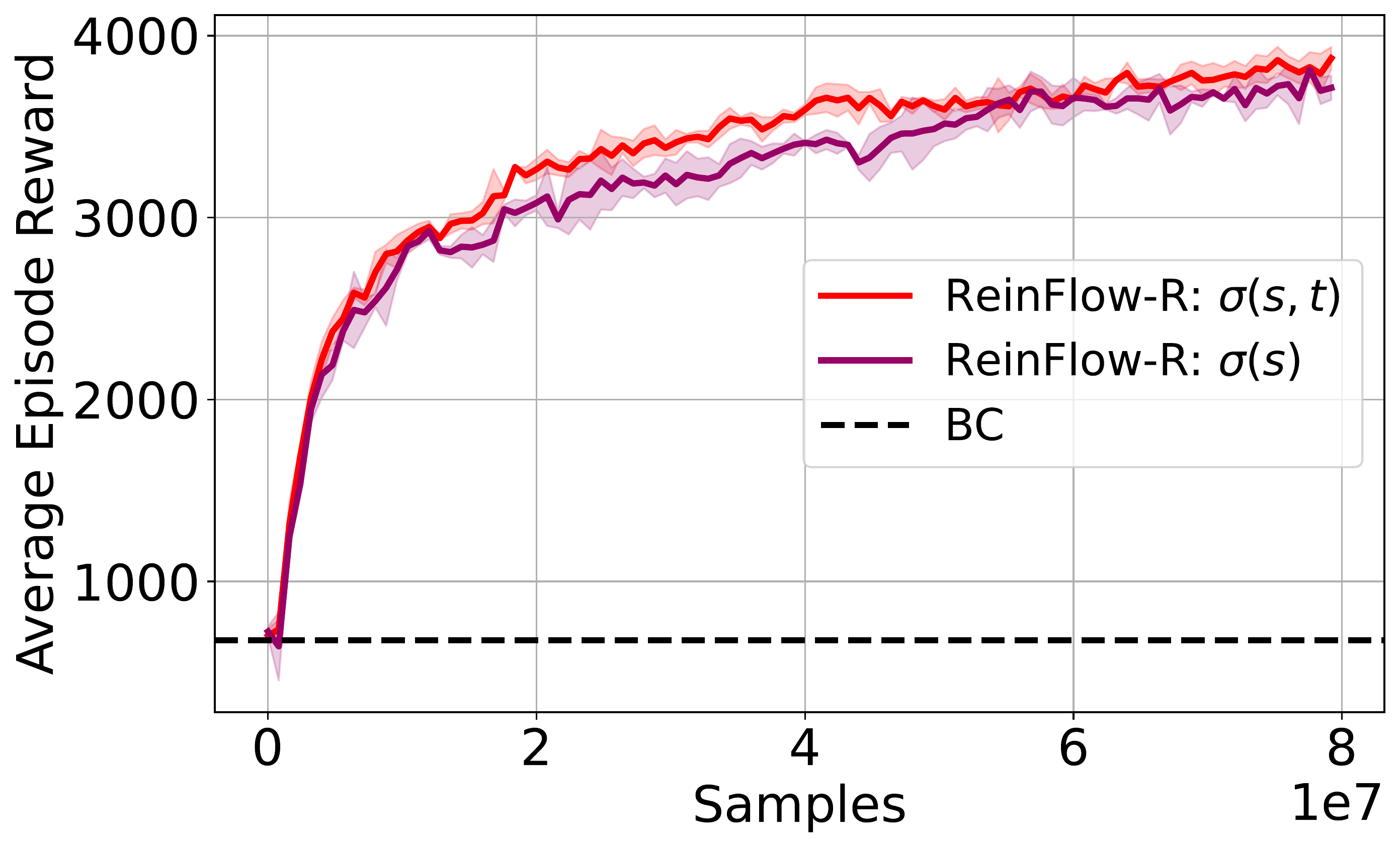
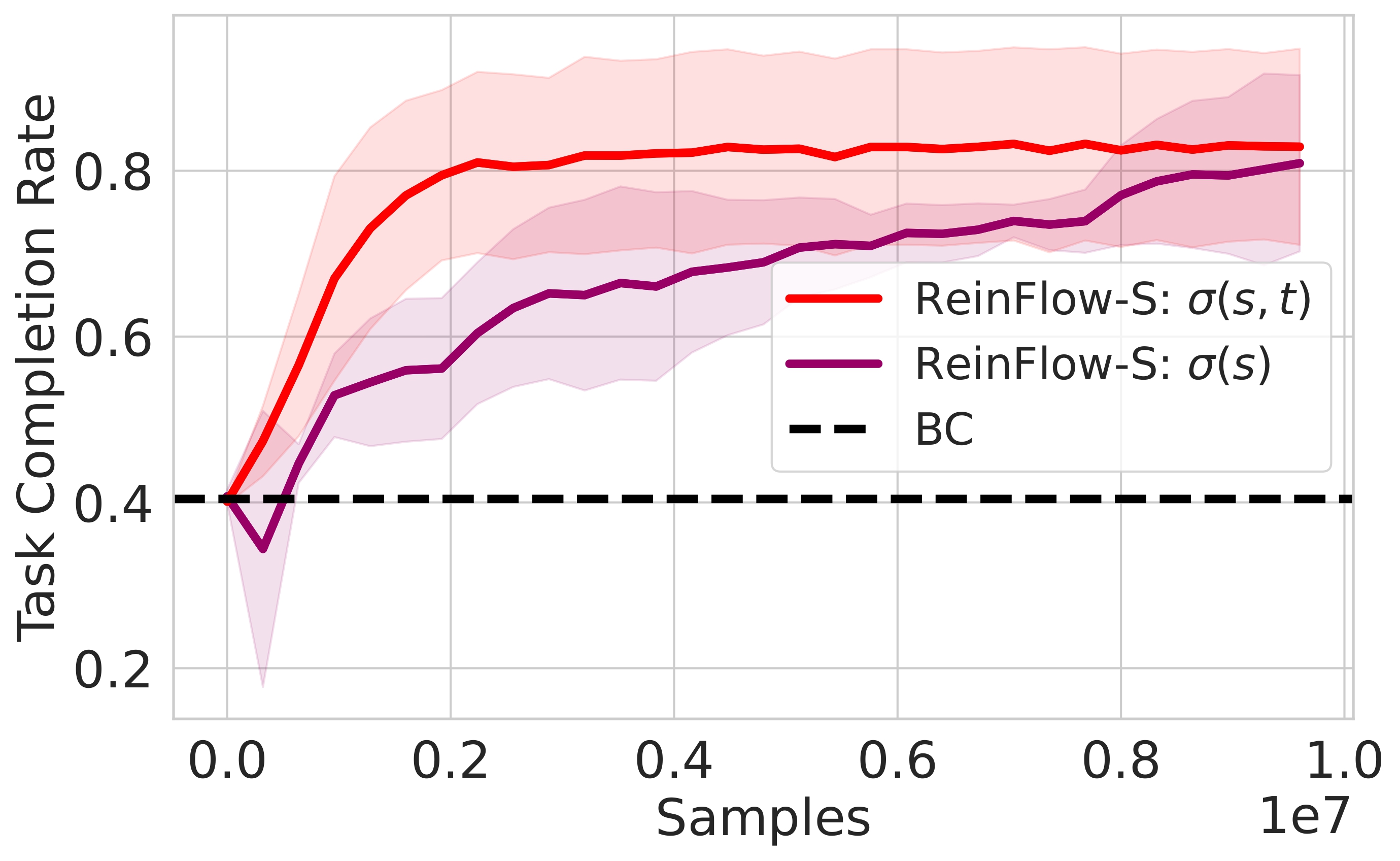
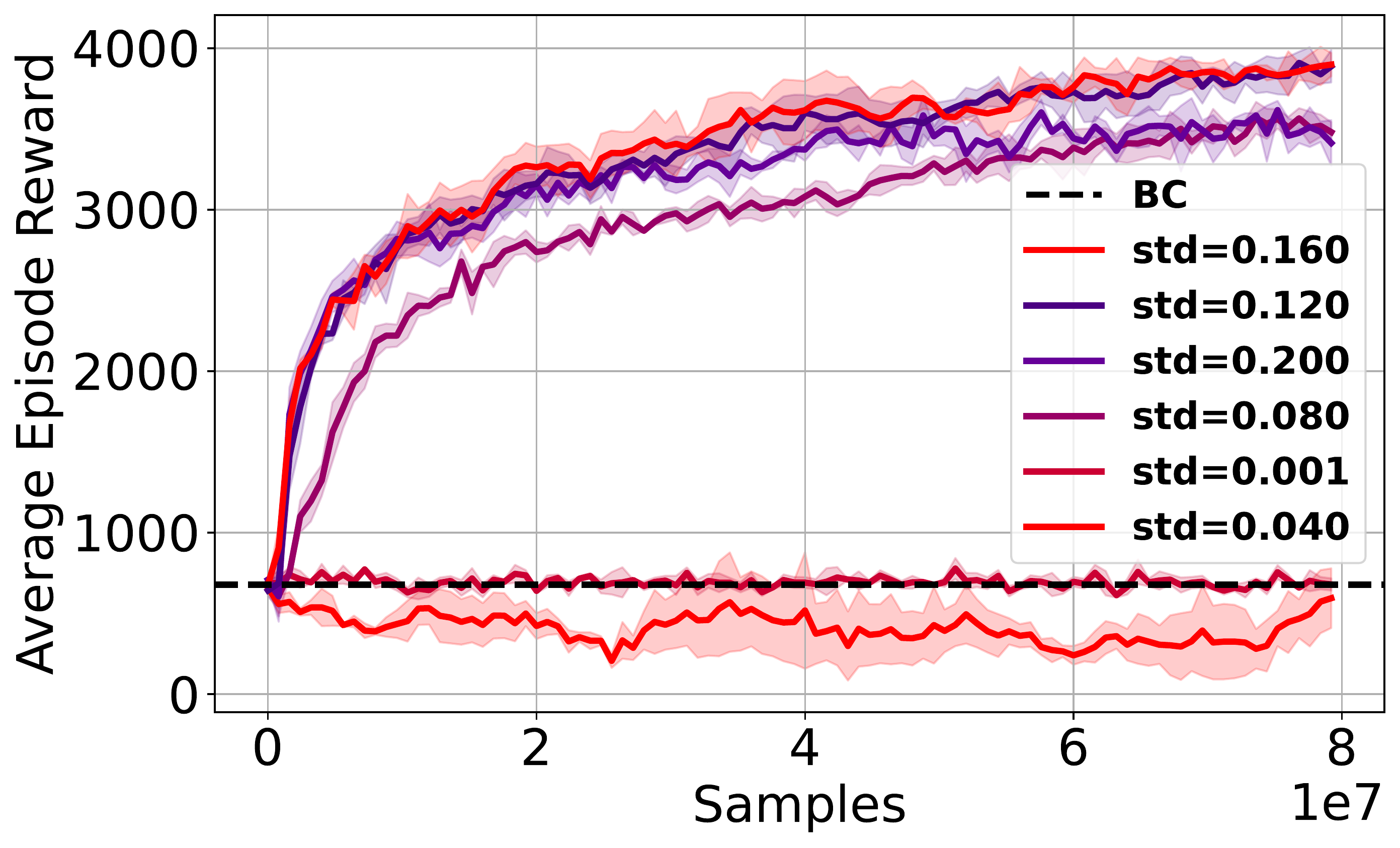
⚖️ Noise magnitude affects exploration: too little traps the policy, too much hurts execution.
🚀 Optimal noise levels enable significant gains, especially in complex tasks.
🔒 Policies become less sensitive to noise once in the correct region.
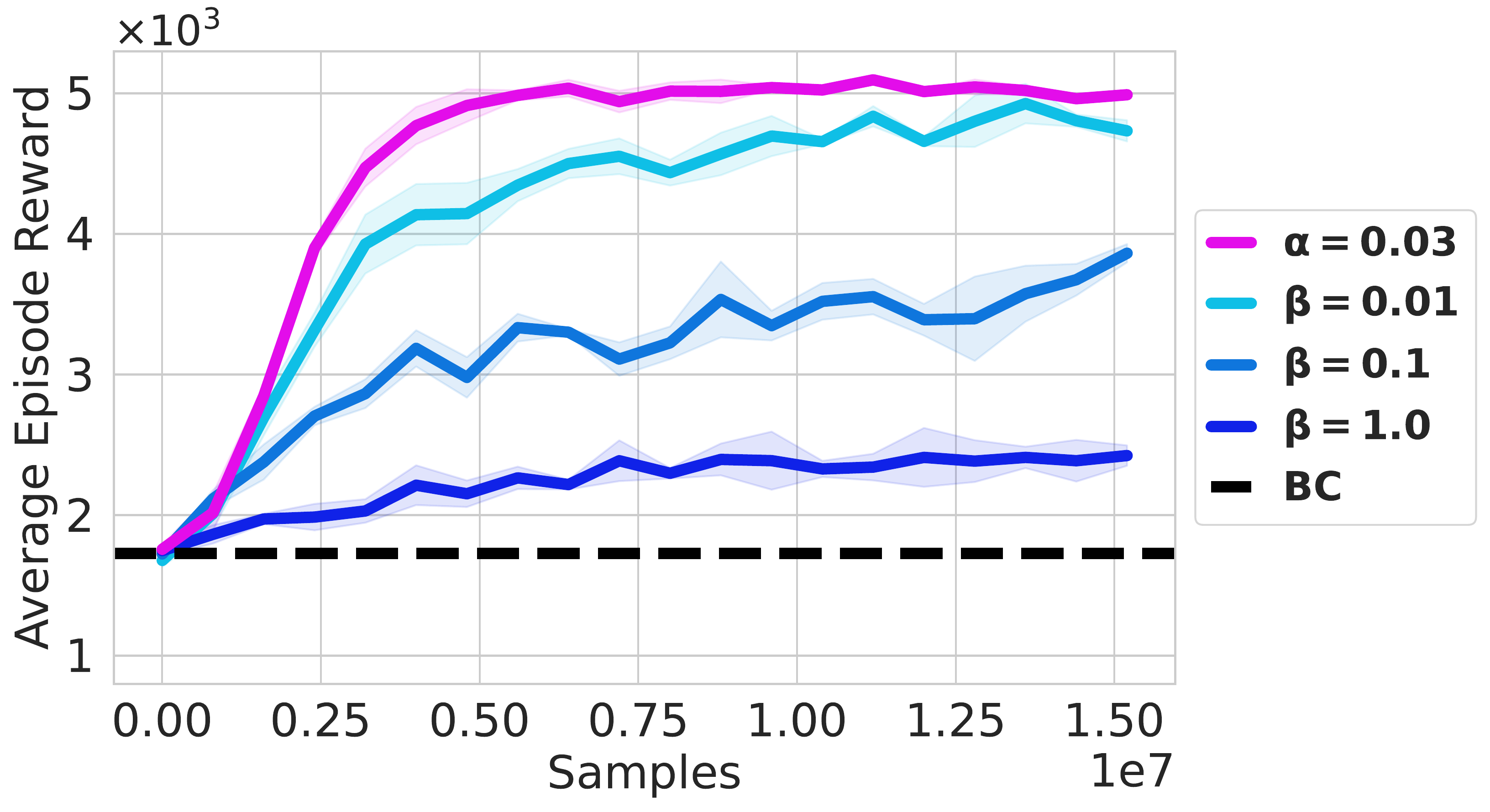
🏅 Entropy regularization promotes exploration, while behavior cloning regularization can trap the policy and is unnecessary.
🏅 Entropy regularization outperforms Wasserstein-2 constraints used in offline RL methods like FQL.
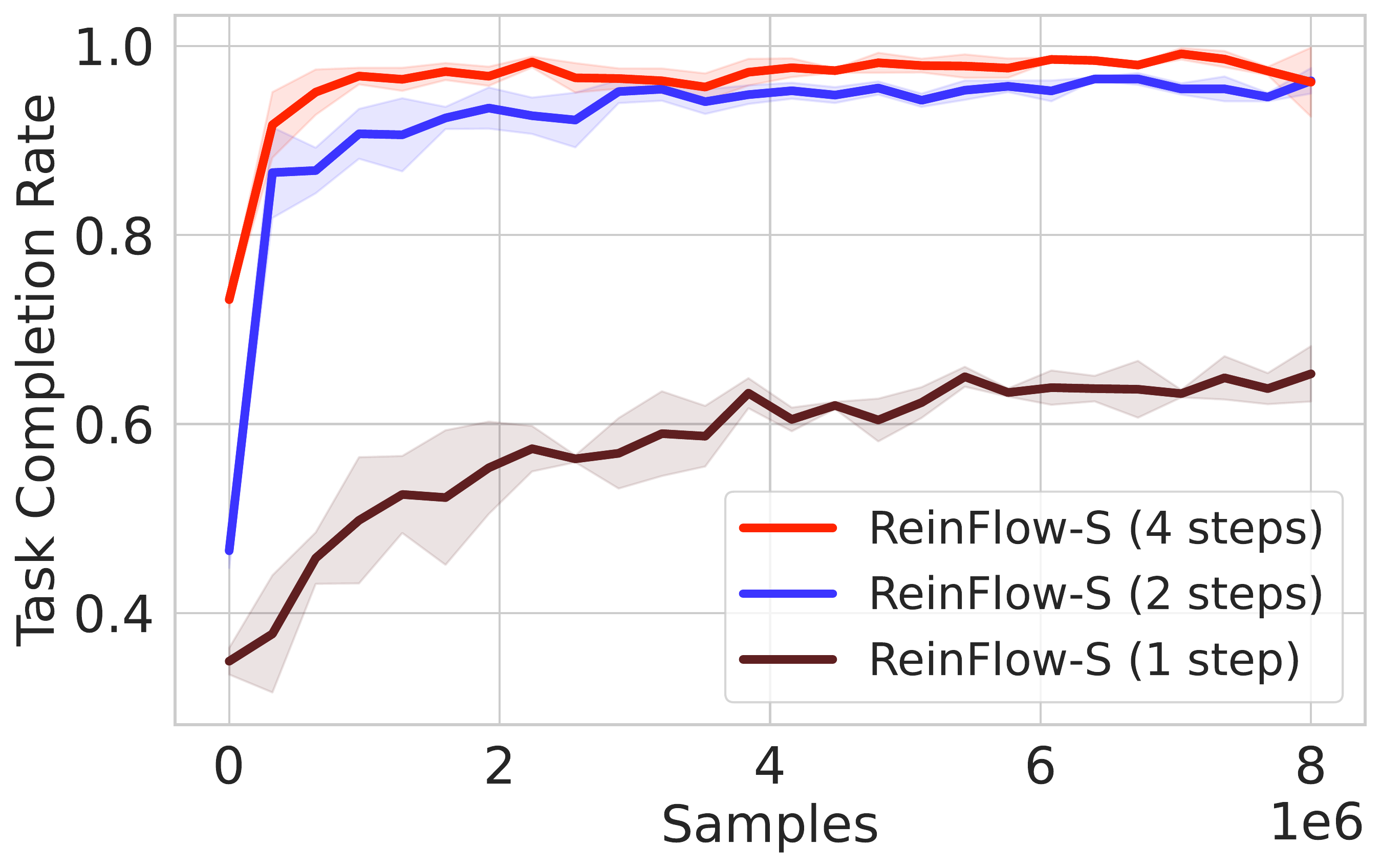
📈 Increasing the number of denoising steps $K$ in ReinFlow boosts initial rewards in Franka Kitchen’s Shortcut Policy but results in rapid reward plateaus, as shown in Fig. 4(A).
🎯 In visual manipulation tasks, lowering noise standard deviation with higher $K$ improves performance for pre-trained policies with low success rates.
| Aspect | Naïve Approach (no noise injection) | ReinFlow |
| Noise Type | Directly compute log probability | Inject learnable noise |
| Error | Unknown Monte-Carlo and discretization error | Controllable and fully known Gaussian noise |
| Accuracy | Inaccurate at few steps | No discretization concerns, accurate for 4, 2, or 1 steps |
| Computation | Compute-intensive in multiple steps | Fast closed-form solution |
\[ \begin{align} \text{SDE general form:}\ \ \qquad \ \ \mathrm{d}X_t &= \quad f(X_t, t) \ \ \ \mathrm{d}t \ \ + \qquad {\color{purple}{ \sigma(X_t, t) }} \, \mathrm{d}W_t \\ \text{ReinFlow's update:}\ \ a^{k+1} - a^k &= \underbrace{v_\theta(t_k, a^k, o) \Delta t_k}_\text{Drift} + \underbrace{{\color{purple}{ \sigma_{\theta'}(t_k, a^k, o) }}\sqrt{\Delta t_k} \ \epsilon}_{\text{Diffusion}} , \quad \epsilon \sim \mathcal{N}(0, \mathbb{I}_{d_A}) \end{align} \]
* Note: The \( \sqrt{\Delta t_k} \) term is omitted when using uniform discretization, as it is equivalent to scaling \( \sigma_{\theta'} \)'s output.
However, the analogy above is just one way to understand our approach, but now how it was invented. Unlike methods that simulate a continuous-time stochastic differential equation (SDE), which need very small steps to avoid errors, ReinFlow models the flow policy as a discrete-time process during inference. This allows it to fine-tune with fewer denoising steps while still accurately evaluating probabilities.






